A vLLM Docker Compose recipe for running Qwen 3.6 27B on dual RTX 3090s (+OpenCode configuration)
I spent some time yesterday getting the new Qwen 3.6 27B model running locally on a (solar-powered) machine with dual RTX 3090 GPUs. With this setup I'm able to achieve around 100 tokens/second and use the model's full 256k context window.
This deployment uses vllm/vllm-openai:latest; no patches or anything else needed:
services:
vllm-qwen36:
image: vllm/vllm-openai:latest
container_name: vllm-qwen36
ipc: host
shm_size: 32gb
ports:
- "8337:8000"
volumes:
- /opt/docker/data/vllm/cache/huggingface:/root/.cache/huggingface
- /opt/docker/data/vllm/cache/vllm:/root/.cache/vllm
environment:
VLLM_ALLOW_LONG_MAX_MODEL_LEN: "1"
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0', '1']
capabilities: [gpu]
command: cyankiwi/Qwen3.6-27B-AWQ-BF16-INT4 --tensor-parallel-size 2 --max-model-len 262144 --gpu-memory-utilization 0.98 --mm-encoder-tp-mode data --kv-cache-dtype fp8 --enable-prefix-caching --enable-chunked-prefill --max-num-batched-tokens 4096 --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coder --max-num-seqs 2 --speculative-config '{"method":"mtp","num_speculative_tokens":2}' --performance-mode interactivity
docker-compose.yml
My OpenCode config for using this locally-hosted model is as follows:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"dzai": {
"npm": "@ai-sdk/openai-compatible",
"name": "DzAI",
"options": {
"baseURL": "http://dzai.my-tailnet.ts.net:8337/v1"
},
"models": {
"cyankiwi/Qwen3.6-27B-AWQ-BF16-INT4": {
"name": "Qwen3.6 27B (256k)",
"tools": true,
"reasoning": true,
"limit": { "context": 262144, "output": 32768 },
"options": {
"temperature": 0.6,
"top_p": 0.95,
"extraBody": {
"top_k": 20,
"presence_penalty": 0.0,
"chat_template_kwargs": { "enable_thinking": true }
}
}
}
}
}
}
}
~/.config/opencode/opencode.json
I thought I'd share this recipe because (1) it's not exactly trivial to discover the right combination of flags that makes this work well, and (2) this is the first coding model I've tried that's plausibly self-hostable and is actually pretty good.
Tests
I tried Qwen 3.6 27B in OpenCode on a couple of my open-source codebases with the prompt "Find any bug in this codebase and propose a fix," and I was impressed with the results (listed below).
I also tried it with my standard GitHub Actions workflow update prompt (listed below), which heavily exercises MCP tool calls, and I was reasonably happy with the result.
Moving forward, I think these will be my standard LLM coding model tests, somewhat like Simon Willison's "draw me a pelican riding a bicycle" test.
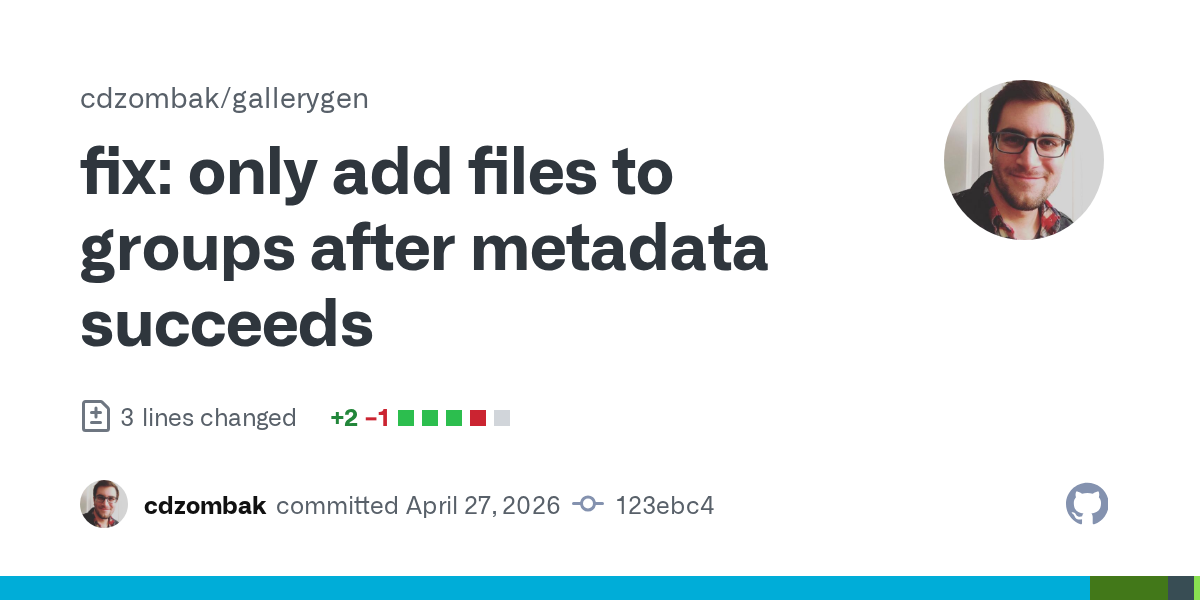
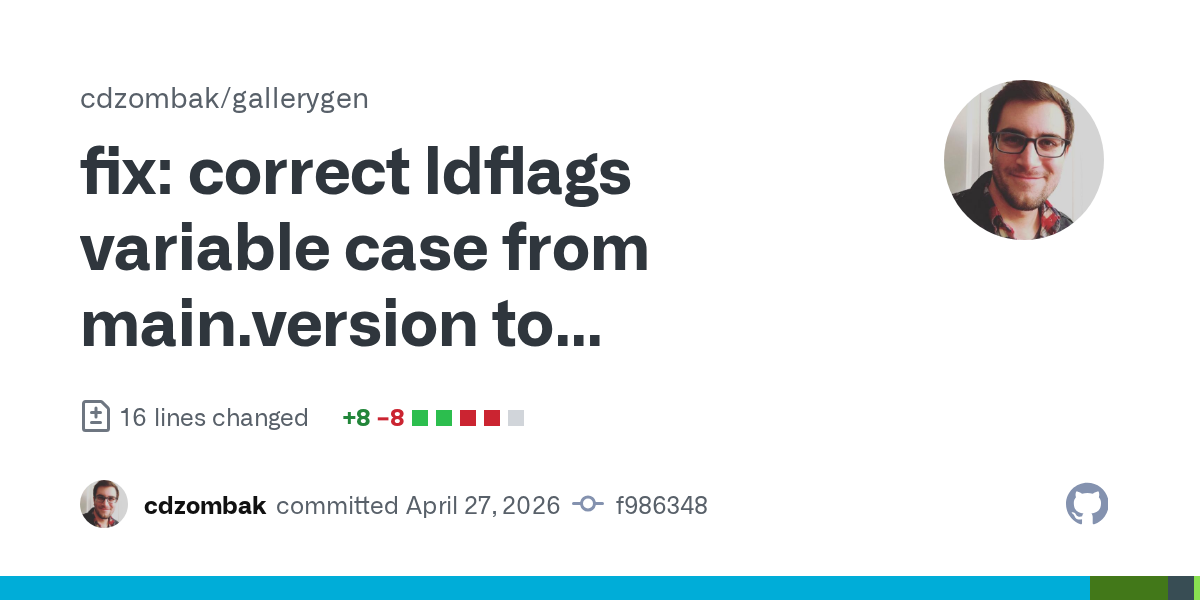
Bugs found & fixed by Qwen 3.6 27B


GitHub Actions Workflow Update Prompt
Update all GitHub Actions in this repo’s workflows to their latest major versions. Use your GitHub MCP tool to verify each action’s latest version and validate that each tag exists. Let me know if there are any breaking changes. Make a PR when complete.